
What this is really about
Local LLMs aren't a goal in themselves — they're a question of finding the right model.
The real challenge rarely lies in the model name, but in the balance between data, security, effort, and useful output.
Some organisations need a controlled AI environment for good reasons. Others assume too quickly that local must automatically be better. Both views are too simplistic. A local or hybrid setup only makes sense once it's clear which requirements truly matter and which architecture actually fits. This applies equally to SMEs with limited resources and to large enterprises.

Architecture and operating model
Especially for local or hybrid setups, architecture has to be shaped from the real working context outward. Only when it is clear which data is involved, which quality level is expected, and how teams actually work, can a useful setup be chosen.
- distinguish data paths and protection levels clearly
- weigh operating effort against real value
- treat governance as a starting condition, not an afterthought
Typical contexts
In demanding enterprise settings, questions about local or controlled LLM setups appear sooner or later. Whether sensitive or confidential data must not flow uncontrolled into external systems, whether regulatory requirements demand strong traceability, or whether some use cases are fine in the cloud while others require more controlled setups — the right answer depends on actual requirements.
The real decision
It's not about local versus cloud as ideology, but about the right model for the actual context. Local LLMs can make sense when data sovereignty, integration requirements, or control needs are high. At the same time, they introduce questions around infrastructure, model quality, maintenance, and user adoption.
digitario helps frame this not as a technology debate, but as a business-relevant architecture and operating decision.
- which data and content are affected
- which quality and latency levels are actually needed
- how much operating and maintenance effort is realistic
- how governance, permissions, and approvals must work
- how the setup integrates into existing processes
OpenClaw in practice
One tool that occupies its own category in this space is OpenClaw — an open-source agent framework that runs locally and connects to a range of AI models. OpenClaw integrates with AI providers such as OpenAI, Anthropic, Google, and others. What sets it apart: OpenClaw never forgets. It retains context and decisions across long time horizons and can execute workflows autonomously around the clock.
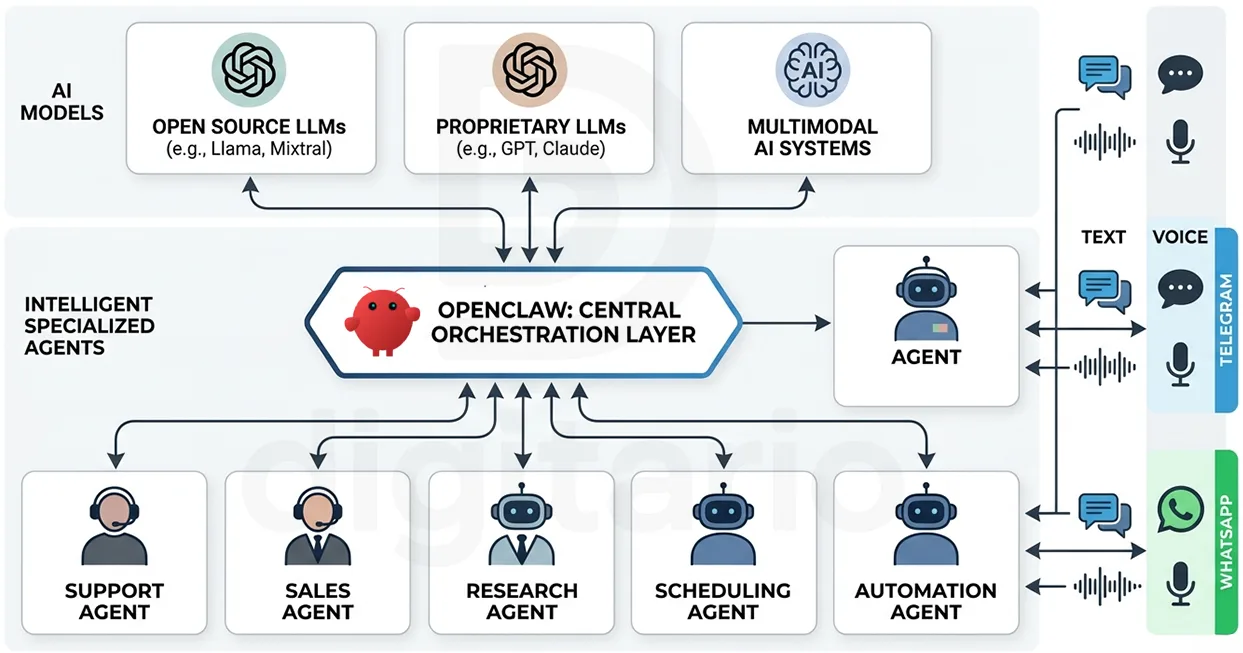
That sounds attractive. And it is. At the same time, OpenClaw is not yet consistently production-ready. Introducing it without the right understanding and setup can create more problems than it resolves. Not every initiative benefits from it — often simpler, faster, and more reliable paths exist.
This is where digitario plays a critical role: assessing whether OpenClaw fits a specific initiative, structuring a well-scoped POC or MVP, and being clear about when genuine production readiness is a realistic expectation.
- which AI models should be connected and why
- how autonomous execution can coexist with governance and oversight
- which processes are truly suited for fully automated workflows
- how a pilot can be scoped clearly before scaling
- whether OpenClaw is actually necessary for this initiative — or whether a simpler solution achieves the same outcome
What digitario actually takes on
digitario doesn't do infrastructure theater. The focus is on deciding which setup genuinely makes sense and how to introduce it responsibly. Data sensitivity, use cases, roles, and protection needs are structured so that a sound decision becomes possible. Responsibilities, permissions, boundaries, and realistic quality expectations are made explicit. From first pilot to a reliable operating pattern, digitario helps turn the topic into real working practice.